Prod Ortam Nedir
Tanım - Üretim Ortamı ne anlama geliyor?
Üretim ortamı, çoğunlukla geliştiriciler tarafından yazılım ve diğer ürünlerin son kullanıcılar tarafından amaçlanan kullanımları için gerçekten çalıştırıldığı ayarı tanımlamak için kullanılan bir terimdir. Bir üretim ortamı, programların çalıştırıldığı ve donanım kurulumlarının kuruluş veya ticari günlük operasyonlar için kurulduğu ve güvendiği gerçek zamanlı bir ayar olarak düşünülebilir.Techopedia Üretim Ortamını Açıklıyor
Bir üretim ortamını tanımlamanın bir yolu, onu bir test ortamıyla karşılaştırmaktır. Test ortamında, bir ürün hala teorik olarak kullanılmaktadır. Kullanıcılar, genellikle mühendisler, hataları veya tasarım kusurlarını arar. Üretim ortamında ürün teslim edildi ve kusursuz çalışması gerekiyor.
İlgili bir terim olan üretim kodu, gerçek zamanlı bir durumda son kullanıcılar tarafından kullanılan veya son kullanıcı işlemleri için yararlı olan kodu ifade eder. Üretim kodunu neyin oluşturduğuna dair bir tartışma, kodun ve teknoloji ürünlerinin ilgili yaşam döngülerinde geçtiği birçok aşamadan dolayı, herhangi bir terimin belirli bir senaryoya resmi olarak uygulanması konusunda çok fazla belirsizlik olduğunu göstermektedir.
Uygulama Yaşam Döngüsü Yönetimi: Geliştirmeden Üretime
tarafından Jason Lee
Bu konuda, kurgusal bir şirketin sürekli geliştirme sürecinin bir parçası olarak test, hazırlama ve üretim ortamları aracılığıyla bir ASP.NET web uygulamasının dağıtımını nasıl yönettiği gösterilmektedir. Konu başlığı boyunca, belirli görevleri gerçekleştirme hakkında daha fazla bilgi ve izlenecek yollara bağlantılar sağlanır.
Konu, kuruluşta web dağıtımıyla ilgili bir dizi öğretici için üst düzey bir genel bakış sağlamak üzere tasarlanmıştır. Burada açıklanan kavramların bazılarını bilmiyorsanız endişelenmeyin; aşağıdaki öğreticiler bu görevlerin ve tekniklerin tümü hakkında ayrıntılı bilgi sağlar.
Not
Kolaylık olması açısından bu konu başlığında, dağıtım işleminin bir parçası olarak veritabanlarının güncelleştirilmesi ele alınmıyor. Ancak, veritabanlarının özelliklerinde artımlı güncelleştirmeler yapmak birçok kurumsal dağıtım senaryosunun gereksinimidir ve bu öğretici serisinin ilerleyen bölümlerinde bunu nasıl gerçekleştirebileceğiniz konusunda rehberlik bulabilirsiniz. Daha fazla bilgi için bkz. Veritabanı Projelerini Dağıtma.
Genel Bakış
Burada gösterilen dağıtım işlemi, Kurumsal Web Dağıtımı: Senaryoya Genel Bakış bölümünde açıklanan Fabrikam, Inc. dağıtım senaryosuna dayanır. Bu konuyu incelemeden önce senaryoya genel bakış konusunu okumalısınız. Temelde senaryo, bir kuruluşun tipik bir kurumsal ortamdaki çeşitli aşamalar aracılığıyla makul derecede karmaşık bir web uygulaması olan Contact Manager çözümünün dağıtımını nasıl yönettiğini inceler.
Üst düzeyde, Contact Manager çözümü geliştirme ve dağıtım sürecinin bir parçası olarak şu aşamalardan geçer:
- Bir geliştirici, Team Foundation Server (TFS) 2010'da bazı kodları denetler.
- TFS kodu derler ve takım projesiyle ilişkili birim testlerini çalıştırır.
- TFS, çözümü test ortamına dağıtır.
- Geliştirici ekibi, test ortamında çözümü doğrular ve doğrular.
- Hazırlama ortamı yöneticisi, dağıtımın herhangi bir soruna neden olup olmayacağını ayarlamak için hazırlama ortamına bir "durum" dağıtımı gerçekleştirir.
- Hazırlama ortamı yöneticisi, hazırlama ortamına canlı dağıtım gerçekleştirir.
- Çözüm, hazırlama ortamında kullanıcı kabul testinden geçer.
- Web dağıtım paketleri el ile üretim ortamına aktarılır.
Bu aşamalar sürekli geliştirme döngüsünün bir parçasını oluşturur.
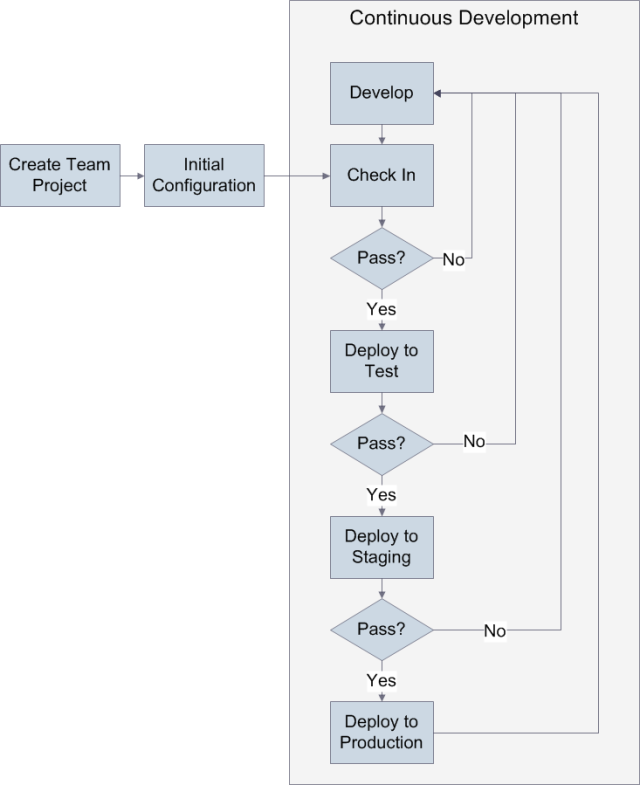
Uygulamada, her aşamaya daha ayrıntılı baktığımızda göreceğiniz gibi süreç bundan biraz daha karmaşıktır. Fabrikam, Inc. her hedef ortam için dağıtım için farklı bir yaklaşım kullanır.
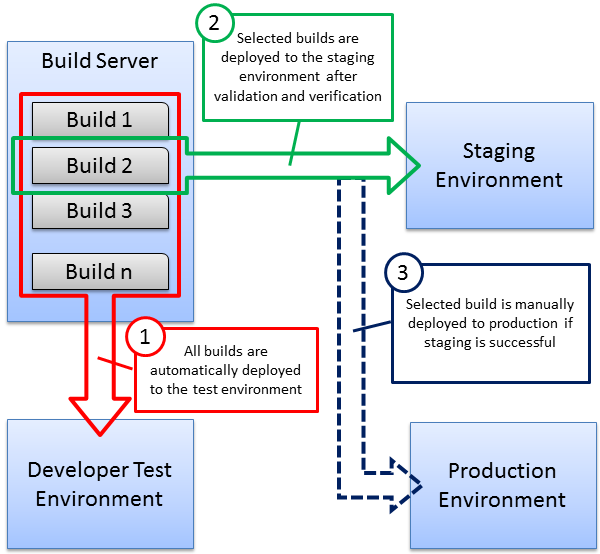
Bu konunun geri kalanında bu dağıtım yaşam döngüsünün bu temel aşamaları incelenir:
- Önkoşullar: Dağıtım mantığınızı uygulamaya koymadan önce sunucu altyapınızı yapılandırmanız gerekir.
- İlk geliştirme ve dağıtım: Çözümünüzü ilk kez dağıtmadan önce yapmanız gerekenler.
- Test için dağıtım: Geliştirici yeni kodu iade ettiğinde içeriği otomatik olarak paketleme ve test ortamına dağıtma.
- Hazırlamaya dağıtım: Belirli derlemeleri hazırlama ortamına dağıtma ve dağıtımın herhangi bir soruna neden olmamasını sağlamak için "durum" dağıtımları gerçekleştirme.
- Üretime dağıtım: Ağ altyapısı uzaktan dağıtımı engellediğinde web paketlerini üretim ortamına aktarma.
Önkoşullar
Herhangi bir dağıtım senaryosundaki ilk görev, sunucu altyapınızın dağıtım araçlarınızın ve tekniklerinizin gereksinimlerini karşıladığından emin olmaktır. Bu durumda Fabrikam, Inc. sunucu altyapısını şu şekilde yapılandırmıştır:
İlk Geliştirme ve Dağıtım
Fabrikam, Inc. geliştirme ekibinin Contact Manager çözümünü ilk kez dağıtabilmesi için önce şu görevleri gerçekleştirmesi gerekir:
- TFS'de yeni bir takım projesi oluşturun.
- Dağıtım mantığını içeren Microsoft Build Engine (MSBuild) proje dosyalarını oluşturun.
- Dağıtım işlemlerini tetikleyen TFS derleme tanımlarını oluşturun.
Yeni Takım Projesi Oluşturma
- TFS yöneticisi Rob Walters, TFS'de Takım Projesi Oluşturma bölümünde açıklandığı gibi uygulama için yeni bir takım projesi oluşturur. Ardından baş geliştirici Matt Hink bir iskelet çözümü oluşturur. Kaynak Denetimine İçerik Ekleme bölümünde açıklandığı gibi dosyalarını TFS'deki yeni takım projesinde denetler.
Dağıtım Mantığını Oluşturma
Matt Hink, Proje Dosyasını Anlama bölümünde açıklanan bölünmüş proje dosyası yaklaşımını kullanarak çeşitli özel MSBuild proje dosyaları oluşturur. Matt oluşturur:
- Dağıtım işlemini çalıştıran Publish.proj adlı bir proje dosyası. Bu dosya, çözümdeki projeleri oluşturan, web paketleri oluşturan ve paketleri hedef sunucu ortamına dağıtan MSBuild hedeflerini içerir.
- Env-Dev.proj ve Env-Stage.proj adlı ortama özgü proje dosyaları. Bunlar, bağlantı dizeleri, hizmet uç noktaları ve web paketini alacak uzak hizmetin ayrıntıları gibi sırasıyla test ortamına ve hazırlama ortamına özgü ayarları içerir. Belirli hedef ortamlar için doğru ayarları seçme yönergeleri için bkz. Hedef Ortam için Dağıtım Özelliklerini Yapılandırma.
Dağıtımı çalıştırmak için, kullanıcı MSBuild veya Team Build kullanarak Publish.proj dosyasını yürütür ve ilgili ortama özgü proje dosyasının (Env-Dev.proj veya Env-Stage.proj) konumunu komut satırı bağımsız değişkeni olarak belirtir. Publish.proj dosyası daha sonra ortama özgü proje dosyasını içeri aktararak her hedef ortam için tam bir yayımlama yönergeleri kümesi oluşturur.
Özel proje dosyalarını oluşturduktan sonra Matt bunları bir çözüm klasörüne ekler ve kaynak denetiminde denetler.
Derleme Tanımları Oluşturma
Matt ve Rob, son hazırlık görevi olarak birlikte çalışarak yeni takım projesi için üç derleme tanımı oluşturur:
- DeployToTest. Bu, Contact Manager çözümünü oluşturur ve her iade işlemi gerçekleştiğinde bunu test ortamına dağıtır.
- DeployToStaging. Bu, bir geliştirici derlemeyi kuyruğa alırsa, kaynakları belirtilen önceki derlemeden hazırlama ortamına dağıtır.
- DeployToStaging-WhatIf. Bu, bir geliştirici derlemeyi kuyruğa alırsa hazırlama ortamına "durum" dağıtımı gerçekleştirir.
Aşağıdaki bölümler, bu derleme tanımlarının her biri hakkında daha fazla ayrıntı sağlar.
Teste Dağıtım
Fabrikam, Inc. geliştirme ekibi, doğrulama ve doğrulama, kullanılabilirlik testi, uyumluluk testi ve geçici veya keşif testi gibi çeşitli yazılım testi etkinlikleri yürütmek için test ortamlarını korur.
Geliştirme ekibi, TFS'de DeployToTest adlı bir derleme tanımı oluşturmuştur. Bu derleme tanımı sürekli tümleştirme tetikleyicisi kullanır. Bu, Fabrikam, Inc. geliştirme ekibinin bir üyesinin her iade işlemi gerçekleştirişinde derleme işleminin çalıştırıldığı anlamına gelir. Bir derleme tetiklendiğinde derleme tanımı şunları yapar:
- ContactManager.sln çözümünü oluşturun. Bu da çözüm içindeki her projeyi oluşturur.
- Çözüm klasörü yapısında birim testlerini çalıştırın (çözüm başarıyla oluşturulursa).
- Dağıtım işlemini denetleen özel proje dosyalarını çalıştırın (çözüm başarıyla oluşturulur ve birim testlerinden geçerse).
Sonuç olarak, çözüm başarıyla oluşturulur ve birim testlerini geçerse web paketleri ve diğer dağıtım kaynakları test ortamına dağıtılır.
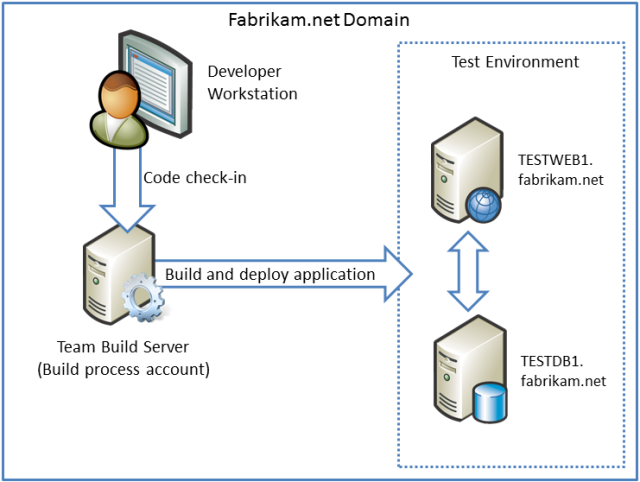
Dağıtım İşlemi Nasıl Çalışır?
DeployToTest derleme tanımı şu bağımsız değişkenleri MSBuild'e sağlar:
DeployOnBuild=true ve DeployTarget=package özellikleri, Team Build çözümün içindeki projeleri oluştururken kullanılır. Proje bir web uygulaması projesi olduğunda, bu özellikler MSBuild'e proje için bir web dağıtım paketi oluşturmasını belirtir. TargetEnvPropsFile özelliği Publish.proj dosyasına içeri aktaracak ortama özgü proje dosyasını nerede bulacağını bildirir.
Publish.proj dosyası, çözümdeki her projeyi oluşturan hedefleri içerir. Ancak, dosyayı Takım Derlemesi'nde yürütüyorsanız bu derleme hedeflerini atlayan koşullu mantık da içerir. Bu, Takım Derlemesi'nin sunduğu birim testlerini çalıştırma gibi ek derleme işlevselliğinden yararlanmanızı sağlar. Çözüm derlemesi veya birim testleri başarısız olursa Publish.proj dosyası yürütülmeyecek ve uygulama dağıtılmaz.
Koşullu mantık, BuildingInTeamBuild özelliği değerlendirilerek gerçekleştirilir. Bu, projelerinizi derlemek için Takım Derlemesi'ni kullandığınızda otomatik olarak true olarak ayarlanan bir MSBuild özelliğidir.
Hazırlamaya Dağıtım
Bir derleme, test ortamında geliştirici ekibinin tüm gereksinimlerini karşıladığında, ekip aynı derlemeyi bir hazırlama ortamına dağıtmak isteyebilir. Hazırlama ortamları genellikle, örneğin sunucu belirtimleri, işletim sistemleri ve yazılımlar ve ağ yapılandırması açısından üretim veya "canlı" ortamın özellikleriyle mümkün olduğunca yakından eşleşecek şekilde yapılandırılır. Hazırlama ortamları genellikle yük testi, kullanıcı kabul testi ve daha kapsamlı iç incelemeler için kullanılır. Derlemeler doğrudan derleme sunucusundan hazırlama ortamına dağıtılır.
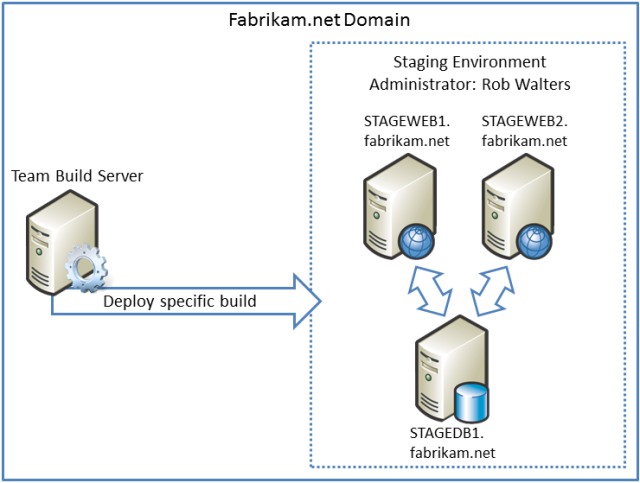
Çözümü hazırlama ortamına dağıtmak için kullanılan DeployToStaging-WhatIf ve DeployToStaging derleme tanımları şu özellikleri paylaşır:
- Aslında hiçbir şey inşa etmezler. Rob çözümü hazırlama ortamına dağıttığında, test ortamında zaten doğrulanmış ve doğrulanmış belirli bir mevcut derlemeyi dağıtmak ister. Derleme tanımlarının yalnızca dağıtım işlemini denetleyebilen özel proje dosyalarını çalıştırması gerekir.
- Rob bir derlemeyi tetiklediğinde derleme parametrelerini kullanarak derleme sunucusundan dağıtmak istediği kaynakları içeren derlemeyi belirtir.
- Derleme tanımları otomatik olarak tetiklenmez. Rob, çözümü hazırlama ortamına dağıtmak istediğinde derlemeyi el ile kuyruğa alır.
Bu, hazırlama ortamına dağıtım için üst düzey bir işlemdir:
- Hazırlama ortamı yöneticisi Rob Walters, DeployToStaging-WhatIf derleme tanımını kullanarak bir derlemeyi kuyruğa alır. Rob, hangi derlemeyi dağıtmak istediğini belirtmek için derleme tanımı parametrelerini kullanır.
- DeployToStaging-WhatIf derleme tanımı, özel proje dosyalarını "durum" modunda çalıştırır. Bu, Rob canlı dağıtım yapıyormuş gibi günlük dosyaları oluşturur, ancak hedef ortamda herhangi bir değişiklik yapmaz.
- Rob, dağıtımın hazırlama ortamı üzerindeki etkilerini belirlemek için günlük dosyalarını gözden geçirir. Rob özellikle nelerin ekleneceğini, nelerin güncelleştirileceğini ve nelerin silineceğini denetlemek istiyor.
- Rob, dağıtımın mevcut kaynaklarda veya verilerde istenmeyen değişiklikler yapmayacağından memnunsa , DeployToStaging derleme tanımını kullanarak bir derlemeyi kuyruğa alır.
- DeployToStaging derleme tanımı özel proje dosyalarını çalıştırır. Bunlar dağıtım kaynaklarını hazırlama ortamındaki birincil web sunucusunda yayımlar.
- Web Farm Framework (WFF) denetleyicisi, hazırlama ortamındaki web sunucularını eşitler. Bu, uygulamayı sunucu grubundaki tüm web sunucularında kullanılabilir hale getirir.
Dağıtım İşlemi Nasıl Çalışır?
DeployToStaging derleme tanımı şu bağımsız değişkenleri MSBuild'e sağlar:
TargetEnvPropsFile özelliği Publish.proj dosyasına içeri aktaracak ortama özgü proje dosyasını nerede bulacağını bildirir. OutputRoot özelliği yerleşik değeri geçersiz kılar ve dağıtmak istediğiniz kaynakları içeren derleme klasörünün konumunu gösterir. Rob derlemeyi kuyruğa alırsa, OutputRoot özelliği için güncelleştirilmiş bir değer sağlamak üzere Parametreler sekmesini kullanır.
DeployToStaging-WhatIf derleme tanımı, DeployToStaging derleme tanımıyla aynı dağıtım mantığını içerir. Ancak, WhatIf=true ek bağımsız değişkenini içerir:
Publish.proj dosyasının içinde WhatIf özelliği, tüm dağıtım kaynaklarının "durum" modunda yayımlanması gerektiğini belirtir. Başka bir deyişle günlük dosyaları, dağıtım devam etmiş gibi oluşturulur, ancak hedef ortamda aslında hiçbir şey değiştirilmez. Bu, gerçekten değişiklik yapmadan önce önerilen dağıtımın etkisini (özellikle nelerin ekleneceğini, nelerin güncelleştirileceğini ve nelerin silineceğini) değerlendirmenize olanak tanır.
Uygulamanızı hazırlama ortamındaki birincil web sunucusuna dağıttıktan sonra, WFF uygulamayı sunucu grubundaki tüm sunucular arasında otomatik olarak eşitler.
Üretime Dağıtım
Hazırlama ortamında bir derleme onaylandığında, Fabrikam, Inc. ekibi uygulamayı üretim ortamında yayımlayabilir. Üretim ortamı, uygulamanın "canlı" olduğu ve son kullanıcıların hedef kitlesine ulaştığı ortamdır.
Üretim ortamı İnternet'e yönelik bir çevre ağındadır. Bu, derleme sunucusunu içeren iç ağdan yalıtılır. Üretim ortamı yöneticisi Lisa Andrews, web dağıtım paketlerini derleme sunucusundan el ile kopyalamalı ve bunları birincil üretim web sunucusundaki IIS'ye aktarmalıdır.
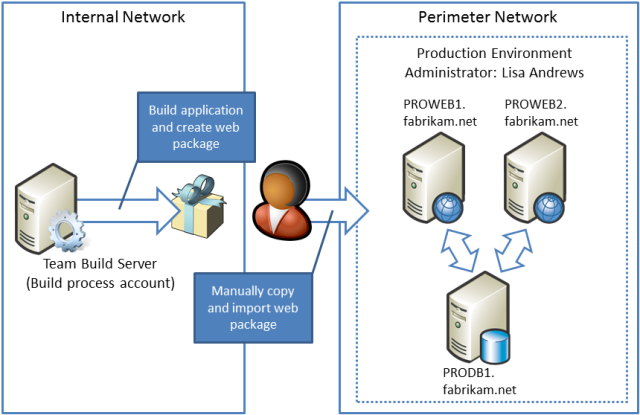
Bu, üretim ortamına dağıtım için üst düzey bir işlemdir:
- Geliştirici ekibi, Lisa'ya bir derlemenin üretime dağıtım için hazır olduğunu önerir. Ekip, Lisa'ya derleme sunucusundaki bırakma klasöründeki web dağıtım paketlerinin konumunu önerir.
- Lisa, derleme sunucusundan web paketlerini toplar ve üretim ortamındaki birincil web sunucusuna kopyalar.
- Lisa, web paketlerini birincil web sunucusunda içeri aktarmak ve yayımlamak için IIS Yöneticisi'ni kullanır.
- WFF denetleyicisi, üretim ortamındaki web sunucularını eşitler. Bu, uygulamayı sunucu grubundaki tüm web sunucularında kullanılabilir hale getirir.
Dağıtım İşlemi Nasıl Çalışır?
IIS Yöneticisi, bir IIS web sitesine web paketleri yayımlamayı kolaylaştıran bir Uygulama Paketini İçeri Aktarma Sihirbazı içerir. Bu yordamın nasıl gerçekleştirileceğine ilişkin izlenecek yol için bkz. Web Paketlerini El ile Yükleme.
Sonuç
Bu konu başlığı altında, tipik bir kurumsal ölçekli web uygulaması için dağıtım yaşam döngüsünün çizimi sağlanmıştır.
Bu konu, web uygulaması dağıtımının çeşitli yönleriyle ilgili rehberlik sağlayan bir dizi öğreticinin bir bölümünü oluşturur. Uygulamada, dağıtım sürecinin her aşamasında birçok ek görev ve önemli nokta vardır ve bunların tümünü tek bir kılavuzda ele almak mümkün değildir. Daha fazla bilgi için şu öğreticilere bakın:
<profiles>
<profile>
<id>dev</id>
<activation>
<activeByDefault>true</activeByDefault>
</activation>
<build>
<resources>
<resource>
<directory>src/main/resources/dev</directory>
</resource>
</resources>
</build>
</profile>
<profile>
<id>prep</id>
<build>
<resources>
<resource>
<directory>src/main/resources/prep</directory>
</resource>
</resources>
</build>
</profile>
<profile>
<id>prod</id>
<build>
<resources>
<resource>
<directory>src/main/resources/prod</directory>
</resource>
</resources>
</build>
</profile>
</profiles>
Tüm piyasa katılımcıları (üyeler, yazılım sağlayıcılar, yatırımcılar) Borsa İstanbul uzak erişim ağı, kolokasyon veya public internet üzerinden piyasa test ortamlarına erişip kendilerine sağlanan emir iletim ve veri yayın kullanıcıları üzerinden testlerini yapabilmektedir.
Pred-Prod Test Ortamı: Üye serbest test ortamıdır. Production sisteminden farklı olarak gelecekte devreye alınacak konfigürasyon ve uygulama değişikliklerini de içerebilmektedir.
Prod-like Test Ortamı: Genellikle yazılım olarak güncel işlem sistemi ile aynı sürüm bulunmaktadır. Fakat yeni devreye alınacak yazılım değişiklikleri ve düzeltmeler, canlı geçişi öncesi bu ortama belli bir süre öncesinden yüklenecek ve üye testine açılacaktır.
Bistech 3.0 Test Ortamı: BISTECH 3.0 olarak adlanlandırılan ve temelde sistemde işlem modüllerinin (partition) sayısının artırıldığı mimari değişikliklerin yer aldığı üye serbest test ortamıdır.
Test Ortamları Bilgilendirme Dokümanı için tıklayınız.
Test ortamlarına bağlantı ve kullanıcı bilgileri talebi için BISTECH Destek ile bağlantıya geçebilirsiniz: [email protected]
Üretim ortamı en iyi pratikleri: performans ve güvenilirlik
Genel bakış
Bu makalede üretim ortamına dağıtılımış Express uygulamaları için en iyi performans ve güvenilirlik pratikleri anlatılıyor.
Bu konu açıkça her iki geleneksel geliştirme ve operasyonları da kapsayarak “devops” dünyasına girer. Buna göre, buradaki bilgiler iki kısma ayrılmıştır:
Kodunuzda yapılacak şeyler
Uygulamanızın performansını iyileştirmek için yapabileceğiniz bazı şeyler:
gzip sıkıştırma kullan
Gzip sıkıştırma, yanıt gövdesininin boyutunu büyük ölçüde azaltabilir ve dolayısıyla da web uygulamanın hızını arttırır. Express uygulamanızda gzip sıkıştırması için compression ara yazılımını kullanın. Örnek olarak:
Üretim ortamındaki yüksek-trafikli bir website için yapılabilecek sıkıştırmanın en iyi yolu ters proxy sevisyesinde uygulamaktır (bakınız Ters proxy kullanımı). Bu durumda sıkıştırma ara yazılımı kullanmak zorunda değilsiniz. Nginx’te gzip sıkıştırmayı devreye alma hakkında daha fazla detay için Nginx dökümantasyonuna bakınız ngx_http_gzip_module modülü.
Senkron fonksiyonlar kullanma
Senkron fonksiyon ve metodlar kod çalıştırma sürecini bir şey döndürene kadar tutarlar. Senkron bir fonksiyona yapılacak bir çağrı birkaç mikrosaniye veya milisaniye içinde dönerler, ancak yüksek-trafikli websitelerde bu çağrılar toplanıp uygulamanın performansını düşürürler. Üretim ortamında bu kullanımdan uzak durun.
Node ve birçok modül kendi fonksiyonlarının senkron ve asenkron versiyonlarını sunmalarına rağmen, üretim ortamında her zaman asenkron versiyonları kullanın. Senkron bir fonksiyonun kullanımının haklı olabileceği tek zaman uygulamanın ilk başlangıcıdır.
Node.js 4.0+ veya io.js 2.1.0+ kullanıyorsanız, uygulamanız senkron bir API kullandığında bir uyarı ve yığın izleme (stack trace) yazdırmak için komut satırı bayrağını kullanabilirsiniz. Elbette bunu üretim ortamında kullanmak istemezsiniz, daha çok bunu kodunuzun üretim için hazır olduğundan emin olmak için. Daha fazla bilgi için bakınız: node komut satırı seçenekler dökümantasyonu.
Loglamayı doğru yap
Genelde, uygulamanızdan loglama yapmak için iki neden vardır: Hata ayıklama ve uygulama aktivitesini loglama için (yani, diğer her şey). Geliştirme ortamında log mesajlarını terminale yazdırmak için veya kullanmak yaygın bir kullanımdır. Ancak hedef bir terminal veya dosya olduğunda bu fonksiyonlar senkrondur, dolayısıyla, çıktıyı başka bir programa aktarmadığınız sürece bunlar üretim ortamı için uygun değiller.
Hata ayıklamak için
Hata ayıklama amacıyla loglama yapıyorsanız, o zaman yerine debug gibi özel bir hata ayıklama modülü kullanın. Bu modül, fonksiyonuna gönderilecek mesajları kontrol etmek için DEBUG ortam değişkenini kullanmanızı sağlar. Uygulamanızı sade asenkron halde tutmak istiyorsanız, yine çıktılarını başka bir programa aktarmanız gerekir. Ama yine de, üretim ortamında hata ayıklamayacaksınız, değil mi?
Uygulama aktivitesi için
Uygulama aktivitesini logluyorsanız (örneğin trafik izleme veya API çağrıları), yerine Winston veya Bunyan gibi bir loglama kütüphanesi kullanın. Bu iki kütüphanenin detaylı bir karşılaştırması için, StrongLoop blog yazısına bakınız Winston ve Bunyan Node.js Loglama Karşılaştırması.
İstisnaları düzgün işle
Node uygulamaları yakalanmamış istisnalar ile karşılaştıklarında patlarlar. İstisnaları işlememe ve gerekli aksiyonları almama Express uygulamanızın patlamasına ve çevrimdışına çıkmasına neden olur. Aşağıdaki Uygulamanızın otomatik olarak yeniden başlatıldığından emin olma tavsiyesine uyarsanız, o zaman uygulamanız bir çökmeden tekrar ayağa kalkabilir. Neyse ki Express uygulamalarının tipik olarak kısa bir başlama süresi var. Yine de patlamalardan kaçınmak gerekir ve bunu yapmak için de istisnaları uygun bir şekilde işlemeniz gerek.
Tüm istisnaları işlediğinizden emin olmak için, aşağıdaki teknikleri kullanın:
Bu konulara girmeden önce Node/Express istisna işleme ile ilgili temel bir anlayışa sahip olmanız lazım: hata-öncellikli geri çağırmaları kullanmak ve hataları ara yazılımda yaymak. Node, asenkron fonksiyonlardan hataları dönmek için “hata-öncellikli geri çağırma” anlayışını kullanır, bu fonksiyonlarda birinci parametre hata objesi ve ondan sonraki parametreleri ise sonuç verileri takip eder. Hata olmadığını belirtmek için ilk parametreye null geçin. İstisnaları anlamlı bir şekilde işlemek için bu geri çağırma fonksiyonlarının hata-öncellikli geri çağırma anlayışını takip etmesi gerek. Ve Express’te ara yazılım zincirinde hataları yaymak için en iyi yöntem fonksiyonunu kullanmaktır.
Hata işleme temelleri hakkında daha fazla bilgi için bakınız:
Ne yapmamalı
Yapmamanız gereken bir şey var, o da bir istisnanın olay döngüsüne kadar çıkarak yayılmasıyla oluşan olayını dinlememek. için bir olay dinleyici eklemek, istisna ile karşılaşan bir sürecin varsayılan davranışını değiştirir; süreç istisna almasına rağmen koşmaya devam edecektir. Bu uygulamanızın patlamasını önlemek için iyi bir yol gibi gözükebilir, ancak uygulamayı yakalanmayan bir istisnadan sonra koşturmaya devam ettirmek tehlikeli bir alıştırmadır ve tavsiye edilmez, çünkü sürecin durumu (state) güvenilmez ve öngörülemez hale gelir.
Ek olarak, kullanımı resmen ham olarak tanınır. Yani olayını dinlemek gerçekten kötü bir fikirdir. Bu yüzden çoklu süreçler ve denetçiler gibi şeyleri tavsiye ediyoruz: patladıktan sonra yeniden başlatma çoğu zaman bir hatayı düzeltmenin en güvenli yoludur.
Ayrıca domains kullanmanızı tavsiye etmeyiz. Genellikle problemi çözmez ve de kullanımdan kaldırılmış bir modüldür.
try-catch kullan
Try-catch senkron kodda oluşan istisnaları yakalamak için kullanabileceğiniz bir JavaScript dili yapısıdır. Try-catch yapısını, örneğin, JSON ayrıştırma hatalarını aşağıda gösterildiği gibi ele almak için kullanın.
Tanımsız değişkenlerde referans hataları gibi kapalı (implicit) istisnaları bulmak için JSHint veya JSLint gibi araçları kullanabilirsiniz.
Buradaki örnek potansyel bir süreç-patlatıcı istisnayı ele alman try-catch kullanımını gösterir. Bu ara yazılım fonksiyonu JSON objesi olan “params” adında bir sorgu alanı parametresi alıyor.
Ancak, try-catch sadece senkron kod için çalışır. Node platformu birincil olarak asenkron olduğundan (özellikle de bir üretim ortamında), try-catch çok fazla istisna yakalamayacaktır.
Promise kullan
Promise’lar kullanan asenkron kod bloklarında herhangi bir istisnayı (implicit / explicit) işleyebilir. Sadece ifadesini promise zincirlerinin sonuna ekleyin. Örneğin:
Şimdi bütün hatalar, asenkron ve senkron olmak üzere, hata işleyici ara yazılıma gider.
Ancak, iki uyarı var:
- Bütün asenkron kodunuz promise döndürmeli (yayıcılar/emitter hariç). Eğer belirli bir kütüphane promise döndürmüyorsa, Bluebird.promisifyAll() gibi bir yardımcı fonksiyon kullanarak temel objeyi dönüştürün.
- Olay yayıcılar (akışlar gibi) yine de yakalanmayan istisnalara neden olabilir. O yüzden hata olayını düzgün bir şekilde ele aldığınızdan emin olur; örneğin:
fonksiyonu ret edilen promise’ları yakalayıp birinci argümanı hata olarak fonkisyonunu çağıran bir sarıcıdır (wrapper). Detaylar için, bakınız Express’te Promise, Generator ve ES7 ile Asenkron Hata Ele Alma.
Promise’lerle hata ele alma ile ilgili daha fazla bilgi için bakınız Node.js’te Q ile Promis’ler – Geri çağrımalara Bir Alternatif.
Ortamınızda / kurulumunuzda yapılacak şeyler
Uygulamanızın performansını iyileştirmek için sistem ortamınızda yapabileceğiniz bazı şeyler:
NODE_ENV değerini “production” olarak ayarla
NODE_ENV ortam değişkeni bir uygulamanın hangi ortamda koştuğunu belirtir (genellikle development veya production olur). Performansı iyileştirmek için yapabileceğiniz en basit şeylerden biri NODE_ENV değerini “production” olarak ayarlamaktır.
NODE_ENV “production” olarak ayarlandığında Express:
- Görüntü şablonlarını önbelleğe atar.
- CSS uzantılarından oluşturulan CSS dosyalarını önbelleğe atar.
- Daha az ayrıntılı hata mesajları üretir.
Yapılan testler sadece bunu yaparak uygulamanın performansının üç kat arttığını gösteriyor!
Eğer özellikle bir ortam için kod yazmak istiyorsanız, NODE_ENV değişkeninin değerini ile kontrol edebilirsiniz. Herhangi bir ortamı değişkeninin değerini kontrol etmenin bir performans düşüşü meydana getirdiğini unutmayın, ve bu yüzden bu işlem idareli yapılmalıdır.
Geliştirme modunda, tipik olarak ortam değişkenlerini interaktif shell’de veya dosyasınızı kullanarak ayarlayabilirsiniz. Ama genellikle üretim sunucusunda bunu yapmamalısınız; onun yerine, işletim sisteminizin init system’ini kullanabilirsiniz (systemd veya Upstart). Bir sonraki kısım genel init system kullanımı hakkında daha fazla detay veriyor, ama NODE_ENV değişkeninin ayarlanması performans için çok önemli olduğundan (ve yapması da kolay olduğundan) burada vurgulanmıştır.
Upstart ile, job dosyanızda ifadesini kullanın. Örnek olarak:
Daha fazla bilgi için bakınız Upstart Giril, Cookbook ve En İyi Pratikler.
Systemd ile, ünite dosyanızdaki direktifini kullanın. Örnek olarak:
Daha fazla bilgi için bakınız Systemd Ünitelerindeki Ortam Değişkenlerini Kullanma.
Uygulamanızın otomatik olarak yeniden başlatıldığından emin olun
Üretim ortamında hiçbir zaman uygulamanızın çevrimdışı kalmasını istemezsiniz. Bu, uygulamanızın veya sunucunun kendisinin patlaması durumunda yeniden başlatıldığından emin olmanız gerektiği anlamına gelir. Bu olaylardan hiçbirinin olmamasını ummanıza rağmen, gerçekçi olarak her iki olasılığı da hesaba katarak:
- Patladığında uygulamayı (ve Node’u) yeniden başlatmak için bir süreç yöneticisi kullanmak.
- İşletim sisteminiz tarafından sağlanan init system’i kullanarak, işletim sistemi çöktüğünde yeniden başlatmak. Init system’i bir süreç yöneticisi olmadan da kullanabilirsiniz.
Node uygulamaları yakalanmayan bir istisna ile karşılaştıklarında patlarlar. En başta yapmanız gereken şey uygulamanızın iyi test edilmiş olmasını ve bütün istisnaları (detaylar için bakınız istisnaları düzgün bir şekilde ele almak) ele aldığını sağlamaktır. Ancak yine de tedbir olarak, uygulamanız patlarsa ve patladığında, yeniden başlatılacağını sağlayan bir mekanizmayı yapmak.
Süreç yöneticisi kullan
Geliştirme ortamında, uygulamanızı basitçe komut satırından veya benzeri bir şeyle başlatırsınız. Ama bunu üretim ortamında yapmak, felakete davetiye çıkarmaktır. Uygulama patladığında, siz tekrar başlatana kadar çevrimdışı kalacaktır. Patladığında uygulamanızın yeniden başlatılmasını sağlamak için bir süreç yöneticisi kullanın. Süreç yöneticisi, uygulamaların dağıtımını (deployment) kolaylaştırıan, yüksek kullanılabilirlik sağlayan ve uygulamayı çalışma zamanında yönetmeye imkan sağlayan konteynerlardır.
Uygulamanızın patladığında tekrar başlatılmasına ek olarak, bir süreç yöneticisi aşağıdakileri yapabilmenizi sağlar:
- Çalışma zamanı performansı ve kaynak tüketimi hakkında içgörüler elde edebilme.
- Performansı iyileştirmek için ayarları dinamik olarak değiştirme.
- Cluster kontrolü (StrongLoop PM ve pm2).
Node için en popüler süreç yöneticileri aşağıdakilerdir:
Bu üç süreç yöneticisinin özellik bazında bir karşılaştırması için bakınız http://strong-pm.io/compare/. Her üçü ile ilgili daha detaylı bir giriş için bakınız Express uygulamaları için süreç yöneticileri.
Uygulamanız zaman zaman patlasa bile, bu süreç yöneticilerinden birini kullanmanız uygulamanızı ayakta tutmak için yeterli olacaktır.
Ancak, StrongLoop süreç yöneticisi özellikle üretim dağıtımını hedefleyen birçok özelliğe sahiptir. Bunları ve ilgili StrongLoop araçlarını aşağıdakileri yapmak için kullanabilirsiniz:
- Uygulamanızı lokal olarak derleyip paketlemek, ve daha sonra güvenli bir şekilde üretim sisteminize dağıtmak.
- Herhangi bir nedenden dolayı uygulamanız patladığında otomatik olarak yeniden başlatmak.
- Kümelerinizi (cluster) uzaktan yönetmek.
- Performansı iyileştirmek ve bellek sızıntılarını teşhis etmek için CPU profillerini ve heap anlık görüntülerini görüntülemek.
- Uygulamanız için performans ölçülerini görüntülemek.
- Nginx yük dengeleyici için entegre kontrol ile birden çok ana bilgisayara kolayca ölçeklendirmek.
Aşağıda anlatıldığı gibi, init systeminizi kullanarak StronLoop süreç yöneticisini işletim sistemi servisi olarak yüklediğinizde, sistem tekrar başlatıldığında bu da tekrar başlatılacaktır. Dolayısıyla, uygulamanızın süreçlerini ve kümelerini sonsuza dek beraber ayakta tutacaktır.
Init system kullan
Güvenilirliğin bir sonraki katmanı, sunucu yeniden başladığında uygulamanızın da yeniden başlatılmasını sağlamaktır. Sistemler çeşitli nedenlerle yine de çökebilir. Sunucu patladığında uygulamanızında yeniden başlatıldığından emin olmak için, işletim sisteminizdeki gömülü init system’i kullanın. Bugün kullanımda olan iki ana init system şunlardır: systemd ve Upstart.
Express uygulamanızda init system’i kullanmanın iki yolu var:
- Uygulamanızı bir süreç yöneticisinde koşun, ve süreç yöneticisini bir servis olarak init system’le yükleyin. Süreç yöneticisi, uygulamanız patladığında yeniden başlatacaktır, ve işletim sistemi de yeniden başlatıldığında, init system süreç yöneticisini başlatacaktır. Tavsiye edilen yaklaşım budur.
- Uygulamanızı (ve Node’u) direkt olarak init system ile koşun. Bu biraz daha basittir, ama süreç yöneticisini kullanmanın verdiği ek avantajları elde etmiyorsunuz.
Systemd
Systemd, bir Linux sistemi ve servis yöneticisidir. Çoğu büyük Linux dağıtımları varsayılan init system olarak systemd’yi benimsemiştir.
Bir systemd servis konfigürasyon dosyasına unit file denir ve dosya ismiyle biter. Aşağıdaki örnek bir Node uygulamasını direkt olarak yöneten bir unit dosyasını gösterir. ile kapanmış değerleri uygulamanız ve sisteminiz ile değiştirin:
Systemd ile ilgili daha fazla bilgi için bakınız systemd referansı (kılavuz).
systemd servisi olarak StrongLoop PM (süreç yöneticisi)
StrongLoop süreç yöneticisini systemd servisi olarak kolaylıkla yükleyebilirsiniz. Bunu yaptıktan sonra, sunucu yeniden başlatıldığında, StrongLoop süreç yöneticisini de otomatik olarak başlatılacak, ve bu da StrongLoop tarafından yönetilen bütün uygulamaların yeniden başlatılmasını sağlayacak.
StrongLoop süreç yöneticisini bir systemd servisi olarak yüklemek için:
Daha sonra, servisi başlatmak için:
Daha fazla bilgi için bakınız Üretim hostu kurmak (StrongLoop dökümantasyonu).
Upstart
Upstart, birçok Linux dağıtımında bulunan sistem başlangıcında görevleri ve servisleri başlatan, kapanma sırasında kapatan ve denetleyen bir sistem aracıdır. Express uygulamanızı veya süreç yöneticinizi bir servis olarak yapılandırabilirsiniz ve bunlar patladığında, Upstart otomatik olarak yeniden başlatacaktır.
Bir Upstart servisi, uzantılı bir job konfigürasyon dosyasında (“job” olarak adlandırılır) tanımlanır. Aşağıdaki örnek, ana dosyası konumunda bulunan “myapp” adında bir uygulama için “myapp” adında bir job yaratmayı gösterir.
Aşağıdakileri içererek konumunda adında bir dosya yaratın (kalın yazıları sisteminizin ve uygulamanızın değerleriyle değiştirin):
NOT: Bu kod Ubuntu 12.04-14.10’da desteklenen Upstart 1.4 ve üstüne ihtiyaç duyar.
Job, sistem başladığında koşması için yapılandırıldığından uygulamanız da işletim sistemiyle beraber başlayacak, ve sistem çöktüğünde veya uygulama patladığında otomatik olarak yeniden başlatılacaktır.
Uygulamanın otomatik olarak yeniden başlatılmasının yanından, Upstart aşağıdaki komutları da kullanmanızı sağlar:
- – Uygulamayı başlat
- – Uygulamayı yeniden başlat
- – Uygulamayı durdur
Upstart ile ilgili daha fazla bilgi için bakınız Upstart Giriş, Kılavuz and En İyi Pratikler.
Upstart servisi olarak StrongLoop süreç yöneticisi
StrongLoop süreç yöneticisini bir Upstart servisi olarak kolaylıkla yükleyebilirsiniz. Bunu yaptıktan sonra, sunucu yeninden başladığında StrongLoop süreç yöneticisini otomatik olarak yeniden başlatır, ve süreç yöneticisinin yönettiği bütün uygulamaları da yeniden başlatır.
Strong Loop süreç yöneticisini bir Upstart 1.4 servisi olarak yüklemek için:
Daha sonra servisi koşmak için:
NOT: Upstart 1.4’ü desteklemeyen sistemlerde bu komutlar biraz farklıdır. Daha fazla bilgi için bakınız Production hostu kurmak (StrongLoop dökümantasyonu).
Uygulamanızı bir kümede (cluster) koş
Çok çekirdekli bir sistemde, bir işlemler kümesi başlatarak bir Node uygulamasının performansını birçok kez artırabilirsiniz. Bir küme, uygulamanın birden fazla örneğini koşar, ideal olarak her bir CPU çekirdeğinde bir örnek olacak şekilde, dolayısıyla da yük ve görevleri örneklerin arasında dağıtır.
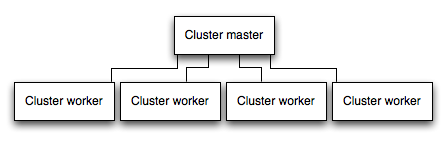
ÖNEMLİ: Uygulama örnekleri ayrı süreçler olarak koştuklarından, aynı hafıza alanını paylaşmıyorlar. Yani, objeler her uygulama örneği için lokaldir. Bu nedenle, uygulama kodunda durumu (state) koruyamazsınız. Ancak, durum ve oturum ile ilgili veriyi depolamak için Redis gibi bir in-memory veri deposu kullanabilirsiniz. Bu uyarı esases, kümeleme birden fazla süreç ya da birden fazla fiziksel sunucularla olsun, tüm yatay ölçekleme biçimleri için geçerlidir.
Kümelenmiş uygulamalarda, çalışan süreçleri (worker process) bireysel olarak geri kalan süreçleri etkilemeden çökebilirler. Performans avantajlarından ayrı olarak, arıza izolasyonu, bir uygulama süreçleri kümesini çalıştırmanın başka bir nedenidir. Ne zaman bir çalışan süreci çökerse, olayı loglayıp ve kullanarak yeni bir süreç yaratmayı unutmayın.
Node’un cluster modülünü kullan
Kümeleme, Node’un cluster modülü sayesinde mümkün hale gelmiştir. Bu, bir ana sürecin çalışan süreçleri üretmesini ve gelen bağlantıları çalışanlar arasında dağıtmasını sağlar. Ancak, direkt olarak bu modülü kullanmak yerine, bu işi otomatik olarak yapan birçok araçtan birini kullanmak çok daha iyi; örneğin node-pm ya da cluster-service.
StrongLoop süreç yöneticisi kullan
Uygulamanızı StrongLoop süreç yöneticisine dağıtırsanız, uygulamanızın kodunu değiştirmeden kümelemenin avantajından yararlanabilirsiniz.
StrongLoop süreç yöneticisi bir uygulamayı koştuğunda, sistemdeki CPU çekirdeği sayısına eşit sayıda çalışanı olan bir kümede otomatik olarak çalıştırır. Uygulamayı durdurmadan slc komut satırı aracını kullanarak kümedeki çalışan süreçlerin sayısını manuel olarak değiştirebilirsiniz.
Örnek olarak, uygulamanızı prod.foo.com’a dağıttığınızı ve StrongLoop süreç yöneticisinin de port 8701’de (varsayılan) dinlediğini varsayarsak, slc kullanarak kümenin büyüklüğünü sekize ayarlamak için:
StrongLoop ile kümeleme hakkında daha fazla bilgi için, StrongLoop dökümantasyonuna bakınız: Kümeleme
PM2 kullan
Uygulamanızı PM2 ile dağıtırsanız, uygulamanızın kodunu değiştirmeden kümelemenin avantajından yararlanabilirsiniz. İlk önce uygulamanızın durumsuz (stateless) olmasını sağlamalısınız, yani süreçte herhangi bir lokal veri saklanmamalıdır (oturum, websocket vb. bağlantılar).
PM2 ile bir uygulama koşulduğunda, seçtiğiniz örnek sayısıyla beraber bir kümede çalıştırmak için küme modunu etkinleştirebilirsiniz, makinedeki mevcut CPU sayısıyla eşleştirilmesi gibi. Uygulamayı durdurmadan komut satırı aracını kullanarak kümedeki süreç sayısını elle değiştirebilirsiniz.
Küme modunu etkinleştirmek için, uygulamanızı bu şekilde başlatın:
Bu aynı zamanda değerini ve değerini de başlangıç çalışan sayısı olarak ayarlayarak bir PM2 süreç dosyası ( ya da benzeri) içinde de yapılandırılabilir
Koşmaya başladıktan sonra, isminde belirli bir uygulama aşağıdaki gibi ölçeklenebilir:
PM2 ile kümeleme hakkında daha fazla bilgi için PM3 dökümantasyonuna bakınız: Cluster Mode
İstek sonuçlarını önbelleğe al
Üretim ortamında performansı artırmak için bir başka strateji, isteklerin sonucunu önbelleğe almaktır, böylece uygulamanız aynı isteği tekrar tekrar sunmak için işlemi tekrarlamaz.
Uygulamanızın hızını ve performansını büyük ölçüde iyileştirmek için Varnish veya Nginx (ayrıca bakınız Nginx Caching) gibi bir önbelleğe alma sunucusu kullanın.
Bir yük dengeleyicisi kullan
Bir uygulama ne kadar optimize edilmiş olursa olsun, tek bir örnek yalnızca sınırlı miktarda yük ve trafiği kaldırabilir. Bir uygulamayı ölçeklendirmenin bir yolu, birden çok örneğini çalıştırmak ve trafiği bir yük dengeleyici aracılığıyla dağıtmaktır. Bir yük dengeleyici kurmak, uygulamanızın performansını ve hızını artırabilir ve tek bir örnekle mümkün olandan daha fazla ölçeklenmesini sağlayabilir.
Yük dengeleyici, genellikle birden çok uygulama örneği ve sunucusuna gelen ve giden trafiği düzenleyen bir ters proxy’dir. Nginx veya HAProxy kullanarak uygulamanız için bir yük dengeleyiciyi kolayca kurabilirsiniz.
Yük dengeleyici kullanırken, belirli bir oturum kimliğiyle ilişkili isteklerin, onları oluşturan sürece bağlanmasını sağlamanız gerekebilir. Bu, oturum yakınlığı (session affinity), veya yapışkan oturumlar (sticky sessions) olarak bilinir, ve oturum verileri için Redis gibi bir veri deposunun kullanılması için yukarıdaki öneri ile ele alınabilir (uygulamanıza bağlı olarak). Tartışma için bakınız Birden çok node kullanmak.
Ters proxy kullan
Bir ters proxy, bir web uygulamasının önünde oturur ve istekleri uygulamaya yeniden yönlendirmenin yanı sıra istekler üzerinde destekleyici işlemler gerçekleştirir. Diğer şeylerin yanı sıra hata sayfalarını, sıkıştırmayı, önbelleğe almayı, dosyaları sunmayı ve yük dengelemeyi de işleyebilir.
Handing over tasks that do not require knowledge of application state to a reverse proxy frees up Express to perform specialized application tasks. For this reason, it is recommended to run Express behind a reverse proxy like Nginx or HAProxy in production.
Uygulama durumu (state) bilgisi gerektirmeyen görevleri bir ters proxy’ye devretmek, özel uygulama görevlerini gerçekleştirmek için Express’i serbest bırakır. Bu nedenle, üretim ortamında Express’i Nginx veya HAProxy gibi bir ters proxy’nin arkasında koşmak tavsiye edilir.
Bu yazımda Azure üzerinde en çok kullanılan servislerden birisi olan ve bir uygulama geliştiren, yöneten, barındıran yada dışarıdan hosting firmalarıyla uygulamalarını barından herkesin kullandığı Azure App Service’den ve App Service Staging Slots mantığından bahsedeceğim.
App Service Nedir ?
En basit tanımıyla Azure App Service HTTP tabanlı bir barındırma hizmetidir. App Service bizlere Web, API, Mobile Backend veya herhangi bir uygulamamızı barındırmamız için bir hosting hizmeti sağlar. Bu hizmeti Azure Platform As a Service mantığında sunarak bize kullanacağımız ortamı Azure Portal’den yönetmemizi sağlar. Arka planda çalışan sanal makinelerle, güvenlik riskleriyle yada güncelleştirmeleri yapmakla uğraşmamıza gerek kalmaz. Uygulamarınız diğer bütün Azure servisleri gibi dakikalar içinde ayağa kaldırılır ve canlı sistemlerde çalışmaya başlarlar. Bu servisin bize sunduğu hosting hizmeti yanında auto-scale, kod yazmadan authentication metodları tanımlama, auto-deployment, hybrid connections gibi çok güçlü özelliklerde bulunuyor. Bu yazıda bahsedeceğim Deployment Slots da bu özelliklerden bir tanesi.
Deployment Slots Nedir ve Nasıl Kullanılır ?
Bana sorarsanız Deployment Slots özelliğini tüm App Service hizmetinden yararlanan kullanıcıların bilmesinde fayda bulunuyor. Bunu bir örnekle açıklamak gerekirse ;
Diyelim ki bir websitemiz var ve URL si datamarket.com.tr. Bu websitesi üzerinde geliştirme yapılıyor ve sürekli olarak yeni versionlar yayınlanıyor. Yapılan bu değişikliklerin bir test aşaması oluyor ve uyumsuzluklar, buglar gibi hataların tespiti için test kullanıcıları tarafından testler yapılıyor. Bu test ortamı genellikle yönetim olarak ayrı bir iş yükü getirir ve production kadar efor ister. Deployment Slot tam olarak bu noktada hayatımıza giriyor. App Service’ de Production Slot’umun yanına kolaylıkla yeni bir slot ekleyebiliyorum. Bu slot kendine has bir instance gibi çalışıyor ve yine kendine has özellikleri oluyor. Sizin seçtiğiniz isimde datamarket-beta.com.tr gibi kendine ait bir URL oluşturuyor ve yeni versionunuzu öncelikle bu test slotuna yüklemenize imkan veriyor. Bu slot isterseniz production slotunun kopyası olarak oluşuyor isterseniz boş bir instance yaratıyor ve size yine kendine ait bir FTP adreside sağlıyor. Uygulamanızı bu test slotunda test ettikten sonra kolayca Swap işlemi yapabiliyorsunuz.
Deployment Slot Yaratma
Deployment Slot yaratmamız için öncelikle bir App Service’ e ihtiyacımız bulunuyor. App Service in içinden Deployment Sekmesinin altında Deployment Slots özelliği bulunuyor.
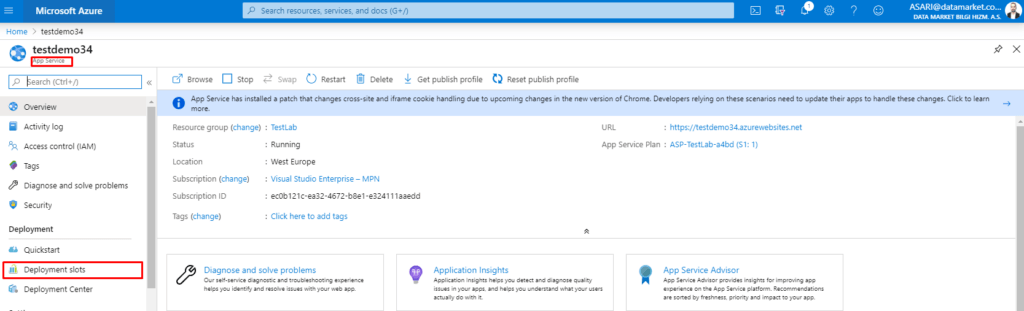
Bu sekmeden Staging Slotlarımızı yönetebiliriz. Sekmeye girdiğimiz zaman karşımıza Production stage olarak karşımıza default bir stage çıkıyor. Bu uygulamızın şuanda çalıştığı slot.
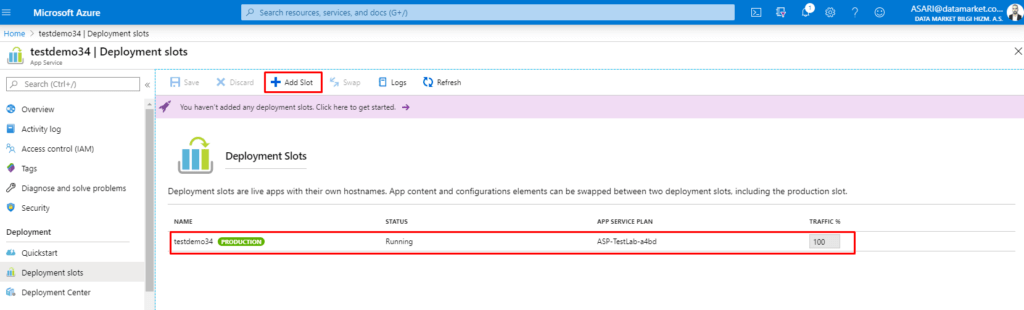
Add Slot diyerek yeni bir Stage ekliyoruz.
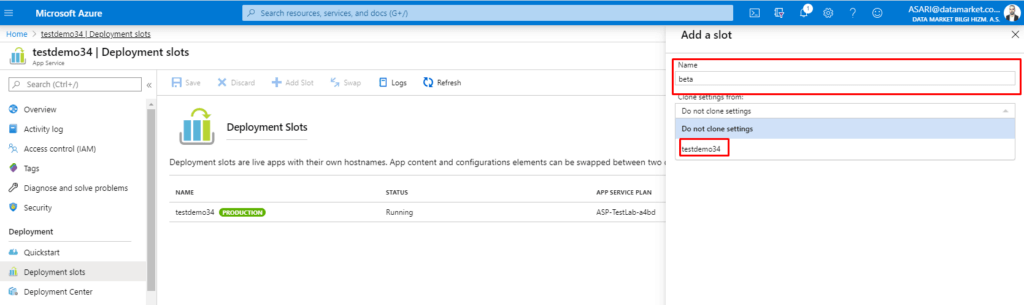
Burada clone settings özelliği ile istersek Production ortamının birebir aynı özellikleriyle yeni bir instance istersek de boş bir instance olarak yaratabiliyoruz.
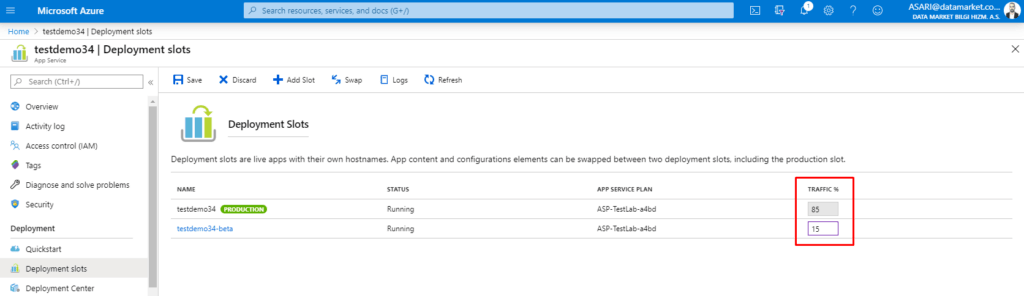
Yeni Slotumuz oluşturuldu ve sağ tarafında traffic seçeneği gözümüze çarpıyor. Traffic özelliği kullanımı çok kolay ve arka planda gerçekten çok verimli bir özellik bunun nedeni ise traffic yüzdelerini yukarıdaki görseldeki gibi ayarladığımız zaman uygulamaya erişen kullanıcıların %85 i production slotuna yönlendirilirken %15’i test slotuna yönlendirilebiliyor ve bunun konfigürasyonu ile biz uğraşmıyoruz. Azure bunu arka tarafta otomatik olarak route ediyor.
Swap İşlemi
Elimizde iki adet Url ve ortam bulunuyor. Bunlar datamarket.com.tr ve datamarket-beta.com.tr. Test ortamımda gerekli deploymenti yaptıktan sonra bu ortamı production’a geçirmek istiyorum. Bunun için yapmam gereken Deployment Slots sekmesinden swap işlemini gerçekleştirmek. Bu işlem arka planda bizim için sırasıyla aşağıdaki işlemleri yapar :
- Production Slotundaki konfigürasyonların tamamını target slot’a uygular (Continuous deployment, Authentication, Connection Strings).
- İlk adımdaki konfigürasyonlar sırasıyla uygulanır ve eğer birisi hata verirse swap işlemi durdurulur ve değişikler geri alınır.
- Sanal IP adresleri değiştirilir ve dolayısıyla Url’ler de değişmiş olur.
Bu işlemi yaptığımızda Production olarak beta slotumuz gözükür ve production URL’sini de test slotumuz almış olur.
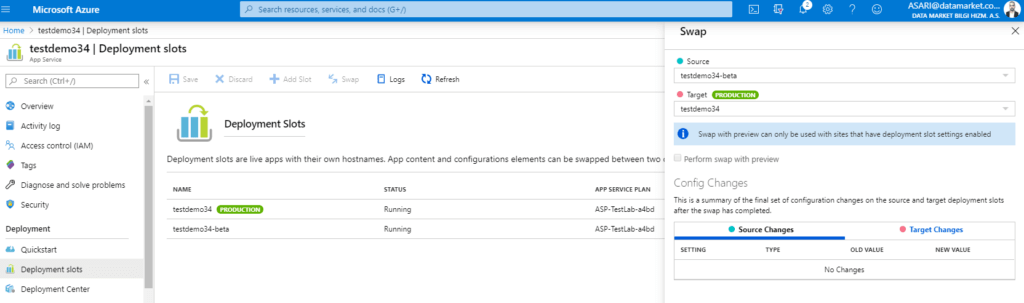
Perform Swap with Preview
Bu seçeneği kullanırsanız App Service aslında normal swap işlemini yapar ve bunu valide eder. Bu işlemin avantajı öncelikli olarak bütün ayarlar sorunsuz bir şekilde uygulanabiliyor mu bunu önceden görebiliyo olmamız. Eğer hiçbir sorun yoksa Swap işlemi gerçekleştirilir.
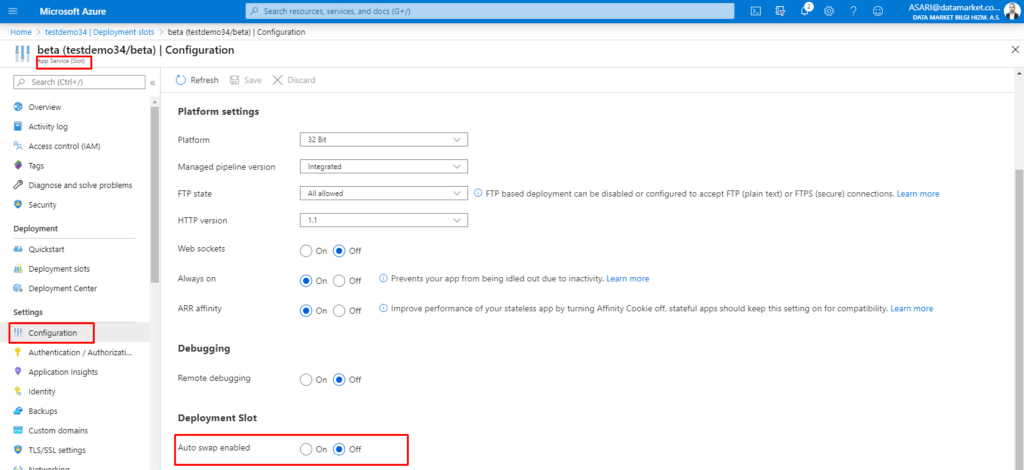
Auto Swap
Auto Swap özelliği slot instance’ından açılabilen ve slota her yeni version deploy edildiği zaman otomatik olarak production slotuyla değişmesini sağlayan bir özelliktir. Bu özelliği açmak için slot instance sayfamızdan configuration sekmesinden General Settings tab’inde bulabilirsiniz.
Azure DevOps ile App Service Slots
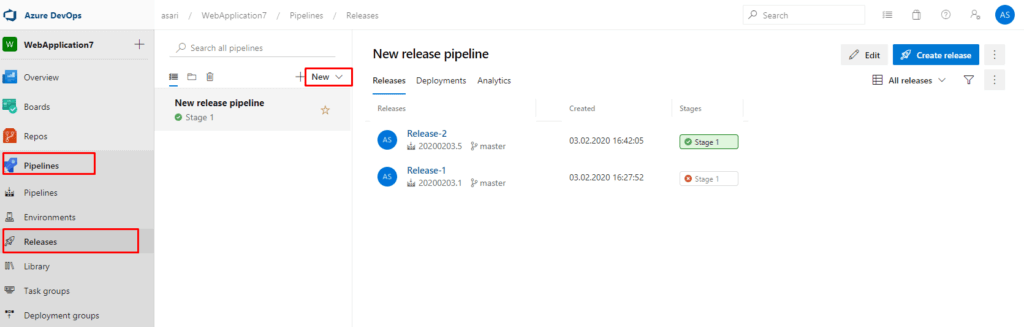
Diyelimki yukarıdaki gibi bir sistemimiz ve uygulamamız var. Ortamımız sürekli olarak geliştiriliyor ve yeni version çıkıyor. Bu çıkan yeni version öncelikle test slotuna daha sonra onaylı bir şekilde production ortamına deploy ediliyor. Bu senaryoyu uçtan uca kurgulayabildiğimiz bir servis bulunuyor ; Azure DevOps Service.
Azure DevOps Service ile CI/CD süreçlerimizi kurgulayabilir ve istenilen gibi öncelikli olarak test daha sonrasında production ortamına deployment sağlayabiliriz. Azure DevOps’un pipelines özelliği ile bu süreci adım adım oluşturalım :
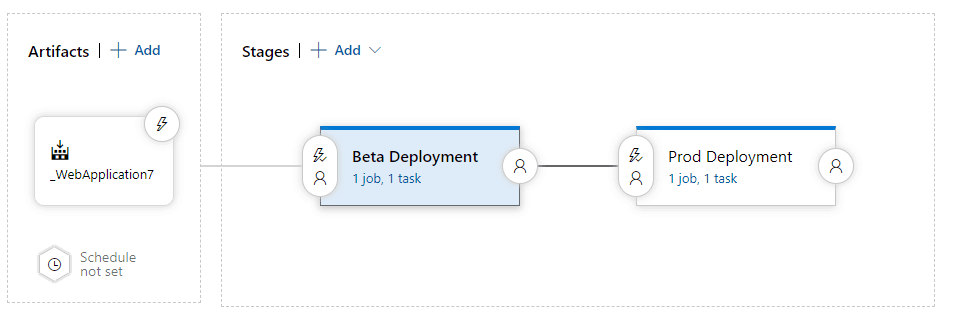
Yukarıdaki görseldeki gibi yeni bir pipeline oluşturuyoruz. Pipeline’ımız iki adımdan oluşacak. Birincisi test deployment ikincisi ise Prod Deployment ve bu süreçler arasında bir onay mekanizması kurgulayacağız.
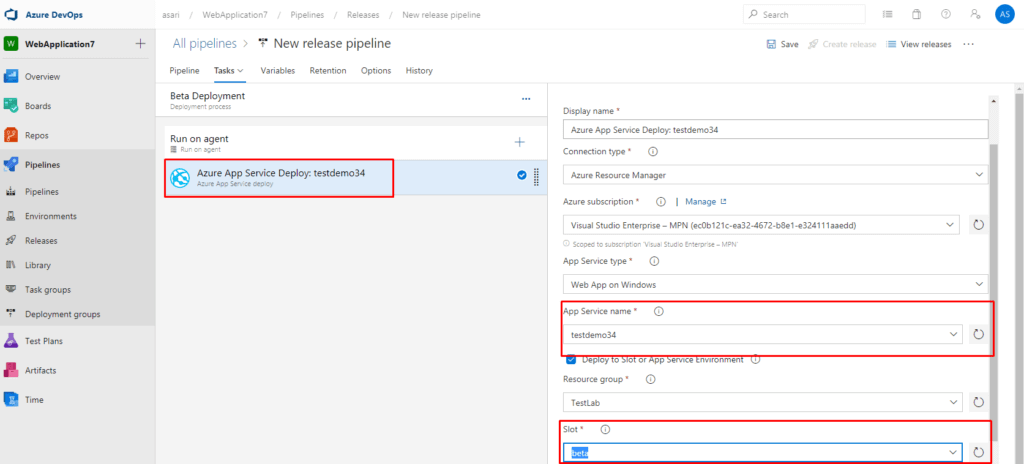
Beta deployment stage’inde App Servicemizin slotuna bir deployment olucağı için ayarlarımızı aşağıdaki gibi uyguluyoruz.
İlgili ayarlarımızı yaptıktan sonra onay mekanizmasını aşağıdaki gibi uyguluyoruz.
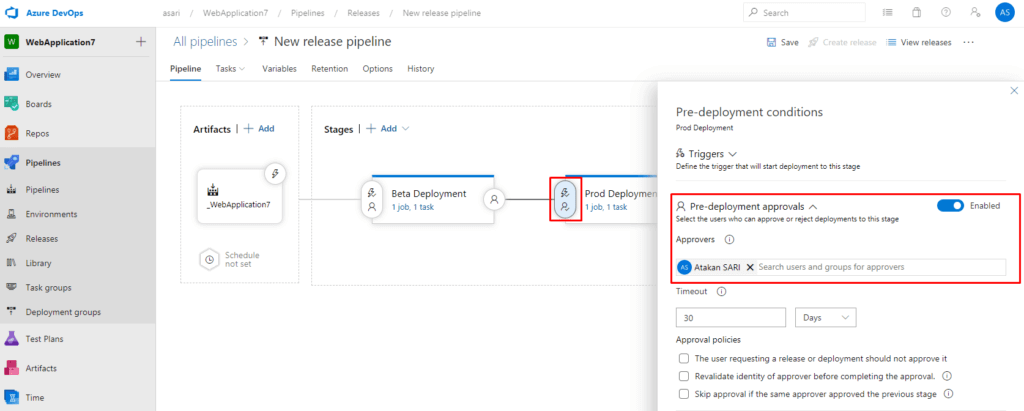
İkinci adımda ise istersek slot swap özelliğini tetikleyebilir istersekte onaydan sonra production ortamınada ayrıca bir deployment alabiliriz.
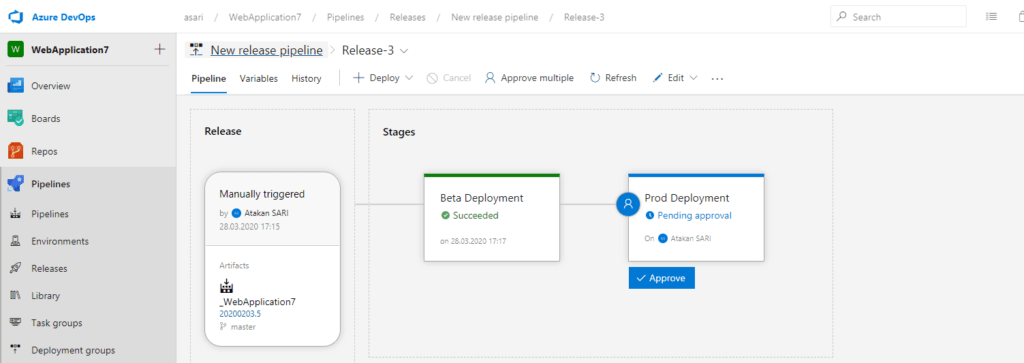
Pipeline’ı çalıştırdığımız zaman aşağıdaki gibi bir onay mekanizması çalışmakta :
Referanslar:
https://docs.microsoft.com/en-us/azure/app-service/overview
https://docs.microsoft.com/en-us/azure/app-service/deploy-staging-slots

App Service Container App
Azure Devops
Prod ortam(Gerçek ortam)
UAT (User Acceptance Testing) Kurgusu
User Acceptance Testing (Kullanıcı Kabul Testi) ürünün/projenin kullanıcılar tarafından kabul edildiği ve ürünün yayın ortamına hazır olduğundan emin olunması sağlayan, production öncesinde kullanılmasını önerilen önemli bir ortamdır. UAT ortamının diğer ortamlara (Development, Test, Staging, Production) göre farkı, test edenler geliştiren ve proje içerisinde yer alan ekip değil, projenin birincil muhattabı kullanıcılardır.
Planlama
UAT (Kullanıcı Kabul Testi), daha önceden belirlenen test senaryolarının tamamlanması sonrasında geçilen adım olduğu için, bu senaryolardan bağımsız olarak, sistemden bağımsız kişiler tarafından yapılmalıdır. Örneğin telefon numarası input testlerinde, test senaryoları ve test eden kişiler (development, test ekibi v.s.) el alışkanlığı ve otomatik doldurma yardımı ile aynı senaryoları test ederken, bağımsız kullanıcılar muhtemelen ilk kez gördükleri ekranda farklı/hatalı girişler yapabilirler.
Ürünün her aşamasında olduğu gibi planlama vazgeçilmezdir. İşlevsellik testlerinde kullanıcıya özellikle test edilmesi gereken senaryolar, input değerlerinden bağımsız olarak sunulmalıdır. Örneğin, “Yeni Üyelik” feature üzerinde duruyorsak, kullanıcılardan özellikle bu alanın yoğun olarak test edilmesi istenmelidir.
Veri Bağlantısı
Bu aşama son viraj olarak değerlendirildiğinden, ortam (canlı) production verilerine bağlı olmalıdır. Canlı verinin kullanıma açılması açısından da kritik bir adım niteliğindedir. Kritik veriler için, canlı veritabanının bir kopyası (replikasyon) tercih edilebilir.
UAT Ne zaman yapılır?
Canlı öncesinde son adım olarak planlansa da, olası senaryolar projeyi tekrar development ortamına götürür. Bu nedenle, mümkünse test > staging > uat > production döngüsünün sürekli yayında olması önerilir. Bu hali ile tamamlanan feature UAT ortamında test edilirken, development sürer. Aksi durumda son adımda karşılaşılan hata döngüyü tekrarlayarak projenin gecikmesine neden olabilir.
Gereklilik
Maalesef UAT ortamı, kritik projeler dışında yaygın olarak kullanılmıyor. Bununla birlikte ürün sahibi açısından önem arz ediyor.
Bunlar ilgini çekebilir
gelişim planı örnekleri 2022 doğum borçlanmasi ne kadar uzaktaki birini kendine aşık etme duası 2021 hac son dakika allahümme salli allahümme barik duası caycuma hava durumu elle kuyu açma burgusu dinimizde sünnet düğünü nasil olmali başak ikizler aşk uyumu yht öğrenci bilet fiyatları antalya inşaat mühendisliği puanları malta adası haritada nerede